A Standalone HTTP Request Parser for C#
A white paper on a missing piece in the .NET ecosystem
What Is an HTTP Request Parser?
When you type your username and password into a login form on a website and click “Submit,” your browser does something invisible: it translates your action into a structured text message and sends it across the network.
Here is a simple HTML form:
<form method="post" action="/login">
<input type="text" name="username" />
<input type="password" name="password" />
<button type="submit">Login</button>
</form>When you fill in “adam” and “secret” and click Login, your browser sends this over the wire:
POST /login HTTP/1.1\r\n
Host: example.com\r\n
Content-Type: application/x-www-form-urlencoded\r\n
Content-Length: 29\r\n
\r\n
username=adam&password=secretThis is raw HTTP — a sequence of bytes following a precise format defined by the HTTP specification. The method (POST), the path (/login), the version (HTTP/1.1), the headers (key-value pairs separated by \r\n), a blank line marking the boundary, and then the body.
This is what arrives at your server’s TCP socket. Not an object. Not a dictionary. Just bytes.
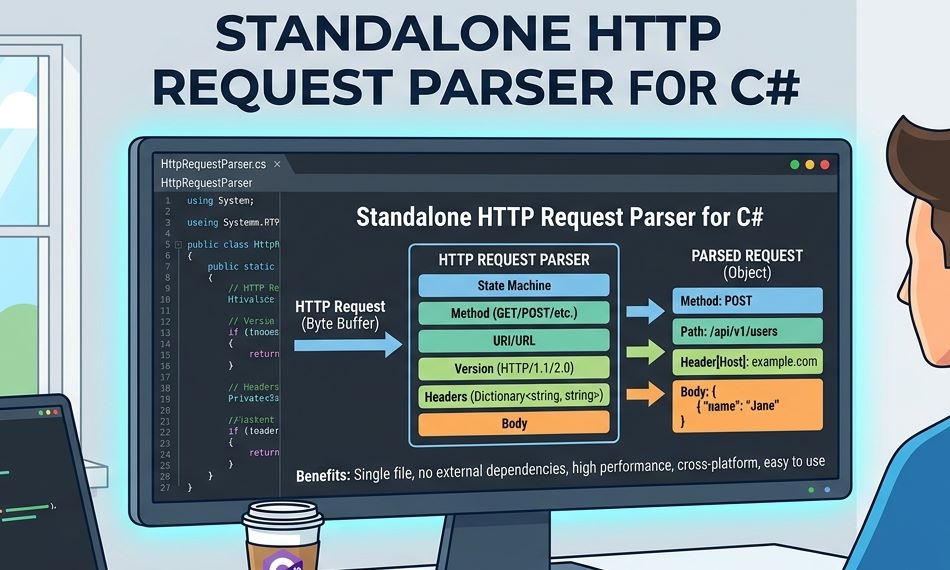
An HTTP request parser is the component that transforms those raw bytes into something your program can work with:
request.Method // "POST"
request.Path // "/login"
request.Headers["Host"] // "example.com"
request.Headers["Content-Type"] // "application/x-www-form-urlencoded"
request.Form["username"] // "adam"
request.Form["password"] // "secret"That is all a parser does. Bytes in, structure out. It performs no networking. It sends no responses. It makes no routing decisions. It reads a byte stream and tells your program what it means.
Every major language ecosystem has one of these as a standalone, reusable component. C has llhttp. Rust has httparse. Python has httptools.
In .NET, HTTP parsers exist — but they are locked inside their frameworks. In ASP.NET Web Forms and MVC, the parser is buried within the IIS integration layer (System.Web). In ASP.NET Core, it lives inside Kestrel. In both cases, the parser is inseparable from the framework that surrounds it.
The Question
Imagine you are a C# developer and you need to handle HTTP requests in your application. Not a web application in the traditional sense — maybe a lightweight webhook receiver, a custom proxy, an embedded endpoint on an IoT device, or a console tool that needs to speak HTTP.
You have two choices:
Choice A: Adopt a framework — ASP.NET Core (Kestrel, middleware pipeline, dependency injection) or classic ASP.NET on IIS (System.Web, the page lifecycle, IIS integration). Either way, you get a production-grade HTTP parser — but it’s welded to the framework. You cannot extract it. You take the whole machine or you take nothing.
Choice B: Write it yourself. Open a TcpListener, read bytes from the socket, split strings, parse headers by hand. This is what the companion article Building a Web Server from Scratch in C# demonstrates — and it works. But your hand-written parser only handles the happy path. It doesn’t handle chunked transfer encoding. It doesn’t guard against malformed headers. It doesn’t enforce size limits. It doesn’t handle the edge cases that turn into security vulnerabilities.
There is no middle ground. No way to say: “I just want the HTTP parser. Give me bytes in, structured request out. I’ll handle the rest.”
This is a false binary. And every other major language ecosystem resolved it years ago.
Why This Matters
The absence of a standalone HTTP parser is not an academic curiosity. It affects real developers building real things.
The IoT developer building an embedded HTTP endpoint on a microcontroller running ASP.NET Core (or ASP.NET classic) is too heavy. The device needs to listen on a port, parse a request, and return a response. Today, this developer writes a fragile custom parser — or doesn’t use C#.
The proxy builder developing a custom reverse proxy or API gateway that needs to inspect HTTP traffic, make routing decisions, and forward requests. This developer needs to read requests without serving them. Kestrel is a server — it wants to own the connection lifecycle. The developer just wants to parse.
The toolmaker building testing infrastructure — a mock server, a traffic recorder, a protocol analyzer. This developer needs to parse captured HTTP bytes from a file or a packet capture. No socket. No server. Just bytes in, structure out.
The webhook receiver — a small service that listens for POST requests from a payment gateway or a CI system. It needs to parse one kind of request, extract the body, and act on it. A full ASP.NET Core application for this is like hiring an architect to install a mailbox.
The solo developer who read the companion tutorial and realized: I could build my own web application without a framework if I just had a reliable parser. Not because frameworks are bad — but because understanding and autonomy matter. Because choosing a framework should be a choice, not a lack of alternatives.
The game developer or mobile developer already writing C# in Unity or .NET MAUI. Their application needs to receive HTTP callbacks — a multiplayer game server accepting match results, a mobile app processing push notification payloads. ASP.NET Core doesn’t belong in these environments. But HTTP does. These developers are already in the C# ecosystem. They just can’t reach the parser.
All of these developers are asking the same question: where does a C# developer go to get a standalone, specification-complete HTTP request parser?
The answer, as of today, is: nowhere.
The Observation
While writing the companion tutorial, something became visible that is easy to overlook:
A ASP.NET Core web application is a console application.
dotnet new web gives you a Program.cs with a Main method. Kestrel is the socket listener. The middleware pipeline is routing logic. Model binding is form data parsing. Everything that a minimal console web server does by hand, ASP.NET Core does through layers of abstraction.
The tutorial builds a working web application — with routing, GET/POST handling, form parsing, and CRUD operations — using nothing but TcpListener and string operations. No ASP.NET. No Kestrel. No framework. And it works.
This reveals something: the HTTP request parser and the web server are separable concerns. They have been bundled together in the .NET ecosystem, but they don’t have to be. The parser is a tool. The server is a tool. A wrench and a car are both useful — but you shouldn’t have to buy the car to get the wrench.
The Gap in .NET — Compared to the Rest
In the C ecosystem, llhttp exists — the HTTP parser used internally by Node.js. It is a standalone library. You hand it bytes. It gives you structured data. It performs no I/O. It has no opinion about your server architecture. It is a pure parser — nothing more, nothing less.
In the Rust ecosystem, httparse exists — zero-copy, zero-allocation, used by Hyper and most Rust web frameworks. Same philosophy. Bytes in, structure out.
In Python, httptools wraps llhttp with Python bindings. Uvicorn uses it. FastAPI uses it indirectly.
PHP occupies a unique position: it also lacks a standalone parser, but developers rarely feel the gap. PHP delegates HTTP parsing to the web server in front of it — Apache, Nginx, or IIS does the work, and PHP receives pre-populated $_GET, $_POST, and $_SERVER arrays. The parser is always someone else’s job. This works because PHP almost exclusively runs behind a web server. Nobody writes a custom proxy or an IoT endpoint in PHP. The deployment model masks the absence.
C# has no such luxury. It is a general-purpose language. Developers do build proxies, game servers, IoT firmware, and custom tools in C# — and every one of them hits the wall that PHP developers never walk toward.
In the .NET ecosystem, HTTP parsers exist — but they are locked inside their frameworks. In classic ASP.NET, the parser is buried within the IIS integration layer (System.Web). In ASP.NET Core, it lives inside Kestrel, tightly coupled to the connection handling, memory pooling, and middleware pipeline. In both cases, you cannot extract the parser. You cannot use it in a console application, an IoT device, a custom proxy, or a testing tool without bringing the entire framework’s dependency graph along.
One notable attempt exists: HttpMachine (https://github.com/1iveowl/HttpMachine.PCL), a C# parser whose state machine is generated by the Ragel compiler from 2011, now maintained as a fork. But it remains obscure, with minimal adoption, and contributing to it requires the Ragel toolchain rather than working in pure C#. The ecosystem gap persists. There is no widely-adopted standalone C# library that accepts raw HTTP bytes and returns a clean, structured request object.
This is the gap.
| Ecosystem | Standalone Parser | Written in |
|---|---|---|
| Node.js | llhttp | TypeScript → C |
| Rust | httparse | Rust |
| Python (fast) | httptools | C (borrowed from Node) |
| Python (pure) | h11 | Python |
| Apache | built-in, not reusable | C |
| nginx | built-in, not reusable | C |
| PHP | none real (doesn’t need one) | — |
| .NET / C# | HttpMachine | C# |
The Precedent: llhttp
llhttp is the most battle-tested HTTP parser in existence. Every HTTP request that reaches a Node.js server passes through it.
Its history is worth noting. The original http_parser was written in C by Ryan Dahl (creator of Node.js). It was later rewritten as llhttp by Fedor Indutny using a novel approach: the parser is generated from a higher-level definition written in TypeScript, using a tool called llparse, which compiles down to C. The C code most people see is not hand-written — it is machine-generated from a more readable specification.
The architecture is a finite state machine. It processes one byte at a time and transitions between states:
- Request line states — parsing the method (
GET,POST, etc.), the URL (path, query string, fragment), and the HTTP version - Header states — parsing field names and values, detecting the final
\r\n\r\nboundary - Body states — identity body (read by
Content-Length), chunked body (hex-prefixed chunks), EOF-terminated body - Special states — connection upgrade detection (WebSocket), error states for malformed input
The parser stores no strings. It fires callbacks — on_url, on_header_field, on_header_value, on_body, on_message_complete — that tell the caller “bytes 14 through 23 are a header field name.” The caller decides what to do with them.
Key edge cases llhttp handles:
- Conflict between
Transfer-EncodingandContent-Lengthheaders (the request smuggling attack vector) - Chunk extensions and trailer headers after chunked bodies
- Obsolete line folding in header values
Connection: keep-alivevsclosesemantics across HTTP/1.0 and HTTP/1.1- Strict size limits on method length, URL length, header count, and header size
This is the blueprint.
The Concept: A C# HTTP Parser
The proposal is not to port llhttp line by line. A direct C-to-C# translation would produce code that compiles but reads like C wearing a C# costume — goto statements, pointer arithmetic translated to array indexing, C memory idioms that don’t belong in managed code.
The correct approach is a re-expression: study llhttp’s state machine architecture, cross-reference it with the HTTP/1.1 specification (RFC 9110 and RFC 9112), and rebuild the state machine natively in C# using the language’s own high-performance primitives.
A key advantage of a C# implementation built on Span<byte> and ReadOnlySpan<byte>: the parser allocates no strings during parsing. It operates directly on the raw byte buffer. No copying. No garbage collection pressure. For high-throughput scenarios — a proxy handling thousands of concurrent connections, an API gateway routing traffic, an IoT device with limited memory — this is not an optimization. It is a requirement. A standalone parser built on these primitives would be lighter than the hand-written string-splitting approach in the companion tutorial, while being orders of magnitude more correct.
The API Surface
At its simplest, the parser could look like this:
var parser = new HttpRequestParser();
parser.OnMethod = (ReadOnlySpan<byte> method) => { /* "GET" */ };
parser.OnUrl = (ReadOnlySpan<byte> url) => { /* "/home?id=1" */ };
parser.OnHeaderField = (ReadOnlySpan<byte> name) => { /* "Content-Type" */ };
parser.OnHeaderValue = (ReadOnlySpan<byte> value) => { /* "text/html" */ };
parser.OnBody = (ReadOnlySpan<byte> chunk) => { /* body bytes */ };
parser.OnMessageComplete = () => { /* request fully parsed */ };
// Feed bytes — can be called incrementally
parser.Execute(buffer);Or, for simpler use cases, a higher-level wrapper:
HttpRequest request = HttpRequestParser.Parse(stream);
string method = request.Method; // "POST"
string path = request.Path; // "/home"
string name = request.Form["name"]; // "Adam Smith"The low-level callback API serves framework builders, proxy developers, and performance-critical applications. The high-level API serves application developers who just want a clean request object — the same developers who read the tutorial and thought, “I wish I could use this in production.”
The State Machine
The core of the parser is a state machine that processes bytes one at a time. A simplified skeleton in C#:
enum ParserState
{
// Request line
MethodStart,
Method,
UrlStart,
Url,
HttpVersionH,
HttpVersionMajor,
HttpVersionMinor,
RequestLineEnd,
// Headers
HeaderFieldStart,
HeaderField,
HeaderValueStart,
HeaderValue,
HeaderLineEnd,
HeadersComplete,
// Body
BodyIdentity, // Content-Length body
BodyChunkSize, // Chunked: reading hex size
BodyChunkData, // Chunked: reading chunk bytes
BodyChunkTrailer, // Chunked: trailing \r\n
BodyChunkComplete, // Chunked: final 0-length chunk
// Terminal
MessageComplete,
Error
}Each byte advances the state machine:
public int Execute(ReadOnlySpan<byte> data)
{
for (int i = 0; i < data.Length; i++)
{
byte b = data[i];
switch (_state)
{
case ParserState.MethodStart:
if (b == ' ' || b == '\r' || b == '\n')
continue; // skip leading whitespace
_state = ParserState.Method;
_mark = i;
break;
case ParserState.Method:
if (b == ' ')
{
OnMethod?.Invoke(data.Slice(_mark, i - _mark));
_state = ParserState.UrlStart;
}
break;
case ParserState.Url:
if (b == ' ')
{
OnUrl?.Invoke(data.Slice(_mark, i - _mark));
_state = ParserState.HttpVersionH;
}
break;
// ... each state handles its byte and transitions ...
case ParserState.Error:
return -1;
}
}
return data.Length;
}This is not complete. This is a structural skeleton — enough to show that the architecture is sound, that the pattern is clear, and that completion is a matter of engineering, not invention.
Security by Specification
The parser’s security model follows directly from the RFCs:
| Concern | Specification | Parser Behavior |
|---|---|---|
| Oversized method | Not specified; practical limit ~8 bytes | Reject after 16 bytes |
| Oversized URL | RFC 9112 recommends 8000 octets minimum | Configurable limit, default 8192 |
| Too many headers | No spec limit | Configurable, default 100 |
| Oversized header value | No spec limit | Configurable, default 8192 bytes |
| Content-Length + Transfer-Encoding conflict | RFC 9112 §6.1: MUST treat as error | Reject with 400 Bad Request |
| Malformed chunk size | Must be valid hex | Reject on non-hex byte |
| Negative or overflow Content-Length | Must be non-negative integer | Reject on parse failure |
Every ambiguous case gets a deliberate decision. Nothing is silently ignored. Nothing falls through to a default. The specification is the map. The parser walks every path on the map and posts a sign at every dead end.
What This Enables
A standalone HTTP parser as a NuGet package changes the answer to the question this paper opened with.
The IoT developer no longer writes a fragile custom parser. They install a package, hand it the bytes from their socket, and get a structured request object. The parsing is correct. The edge cases are handled. They focus on their application logic.
The proxy builder no longer fights Kestrel’s connection lifecycle. They read bytes from one socket, parse the request, make their routing decision, and forward the bytes to another socket. The parser doesn’t care what happens next. It just parses.
The toolmaker builds a mock server in 50 lines — a TcpListener, the parser, and a switch statement. Traffic analysis becomes a loop: read bytes from a capture file, feed them to the parser, inspect the structured output. No server needed.
The webhook receiver becomes a single-file console application. Listen, parse, extract, act. No framework. No configuration. No ceremony.
The solo developer — the one who read the tutorial and built a web server from scratch — drops in the parser package and replaces their hand-written string splitting with a specification-complete implementation. Their console web application is now production-grade. They didn’t adopt a framework. They adopted a tool.
The game developer adds the parser to their Unity project. The multiplayer server now parses match results from HTTP callbacks correctly — chunked encoding, edge cases, and all — without pulling ASP.NET Core into a game runtime where it doesn’t belong. The mobile developer does the same in .NET MAUI. HTTP parsing arrives where C# already lives.
The parser becomes infrastructure. The framework becomes optional. The developer chooses their own architecture — but the HTTP parsing is correct either way.
The Porting Process
There are two paths to bringing a standalone HTTP parser to .NET.
Path A: A native wrapper around llhttp. Compile llhttp as a native library and call it from C# through P/Invoke. The llhttp API is small — a dozen functions, a handful of callbacks. A working prototype is achievable in a weekend; a polished NuGet package with cross-platform native binaries (Windows, Linux, macOS) in roughly two weeks. This is the fast path. It delivers a battle-tested parser immediately. The trade-offs are platform-specific native binaries, marshalling overhead on callbacks, and a debugging experience that drops into unmanaged code. But it works, and it ships.
Path B: A pure C# reimplementation. Study llhttp’s state machine, cross-reference with the RFCs, and rebuild it natively in C# using Span<byte> and ReadOnlySpan<byte>. No native dependencies. No interop boundaries. Runs anywhere .NET runs. This is the slower path — but it produces a parser that is truly native to the ecosystem.
These paths are not mutually exclusive. The pragmatic sequence is: ship the wrapper, let developers use it, and build the pure implementation in parallel. The wrapper proves the demand. The pure implementation fulfills the vision.
For anyone pursuing Path B, the process has a clear sequence:
Phase 1 — State Map Extraction Analyze llhttp’s state machine. Document every state, every transition, every edge case. Cross-reference with RFC 9112. Produce a complete state transition table.
Phase 2 — API Design Define the C# API surface. Callback-based for low-level use. Object-based for high-level use. Both backed by the same state machine.
Phase 3 — Core Implementation Build the state machine in C# using Span<byte>, ReadOnlySpan<byte>, and ReadOnlySequence<byte>. No string allocation during parsing. No I/O. Pure byte processing.
Phase 4 — Edge Case Coverage Implement every documented HTTP structure: chunked encoding, trailer headers, chunk extensions, obsolete line folding, connection semantics, size limits. Each one mapped to a specific RFC section.
Phase 5 — Fuzz Testing Feed the parser garbage. Malformed headers. Truncated bodies. Conflicting headers. The request smuggling patterns. Oversized fields. Binary noise. Every byte combination that could cause a crash, a hang, or a silent misparse. This phase is where trust is earned.
Estimated scope: 2–3 months for a focused developer with AI assistance. Not because the code is difficult — but because correctness is.
The Invitation
This white paper does not contain a finished library. It contains a visible possibility.
The C and Rust ecosystems separated the HTTP parser from the server long ago. The .NET ecosystem never did. This paper proposes that it should — and lays out the architectural path to get there.
The tutorial article demonstrates that a C# console application can be a web server and a web application. This white paper proposes the next step: a production-grade HTTP parser that makes that console application safe.
This is open-source, gift-mode work. The concept is here. The architecture is documented. The state machine skeleton is runnable. The specification is public (RFC 9110, RFC 9112).
The door is open. Whoever walks through it — continues the work.
This white paper accompanies the article Building a Web Server from Scratch in C#, which demonstrates a working web application built with nothing but TcpListener and string operations.
The llhttp parser (MIT License) is maintained at github.com/nicolaracco/llhttp. RFC 9110 (HTTP Semantics) and RFC 9112 (HTTP/1.1) are published by the IETF.